

dotCMS Site Search utilizes ElasticSearch to create independent indexes for different groups of content on your Site. Each of the indexing processes can be scheduled to run at different times, and any content can be indexed and searched in one or more separate or overlapping indices.
Note:
- Site Search is an Enterprise Edition feature only.
- Site Search indices are separate from the standard content index used to search for and access content with standard content pulls and through the dotCMS back-end.
What is and is not Included in a Site Search Index
The Site Search indexes all Pages, Files and URL Mapped content which match the specified locations for the Site Search indexing job. The Site Search does not crawl your site. Instead it searches the content repository on the speicified site(s) and serializes the content to make it searchable. The following limitations apply to Site Search indices:
- Only content of a Content Types with a URL Map are added to the Site Search index.
- Only text which is either displayed on a Page or within a content item or File OR included in the meta keywords HTML tag are indexed.
- Text which is included within HTML tags or tag properties (e.g. “style” properties) are not indexed.
- Content fields which are not displayed on a Page are not indexed.
- This means, for example, that Tags applied to the content are not searcheable.
- To make any undisplayed fields on content searchable with the Site Search index, you may either:
- Explicitly display the value of the fields on the page, or
- Add the appropriate text to the
<meta name="keywords">tag on the page where the content is displayed.
- For URL Mapped content, any changes made to include additional content in the index must be done on the Detail Page for the Content Type.
- Site Search results are NOT permissioned.
- Site Search will only index Pages, Files or URL Mapped content which are viewable by the CMS Anonymous Role.
- For this reason, Site Search cannot be used to index or search non-public pages (pages requiring a site login to access).
Meta Keywords Tag
You may specify keywords to be indexed by including them in the HTML <meta name="keywords"> tag, as in the following example:
<meta name="keywords" content="$keywords">
The keywords “content” property can contain any number of keywords, separated by spaces and/or punctuation. The contents of the “content” property will be parsed by Elasticsearch in the same way all other content fields are parsed (including indexing words separated by spaces as separate terms, regardless of any punctuation used).
When searching a Site Search index, you can explicitly reference any content included in the keywords meta field by specifying the keywords field in the query, as in the following example:
#set($searchresults = $sitesearch.search("+keywords:invest*", 0, 10))
Note:
- The templates included in the dotCMS starter site do not set the keywords meta tag.
- Whether you use the default dotCMS templates, or create your own, you must explicitly add the keywords meta tag if you wish the keywords to be indexed by Site Search.
- The keywords are indexed separately.
- Though in previous versions it was necessary to use wildcards to match keywords properly, wildcards are no longer necessary unless you wish to ensure matching of multiple forms of the same word.
Multi-lingual Content and Pages
Since Site Search indexes Pages (including URL-mapped content via the Detail page), if you create Site Search indexes for different languages, the indexes will be created based on the language of the Page, not based on the language of the content displayed within the Page. This means that, if you wish to be able to create separate Site Search indexes for different language versions of your content, you will need to create separate Pages for each language, to ensure that the content in each language is indexed separately from each other.
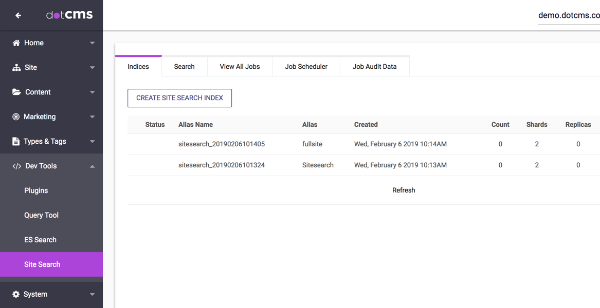
Creating a New Site Search Index
To create a new Site Search Index:
- Select Dev Tools -> Site Search.
- Select the Indices tab.
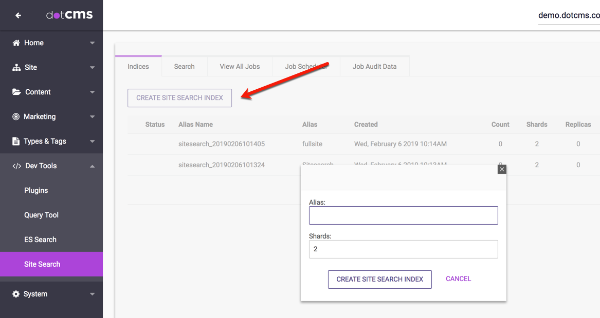
- Click CREATE SITE SEARCH INDEX. In the popup:
- Enter an Alias (friendly name) for the index.
- Enter the number of Shards for the index.
- The number of shards is used to tune Elasticsearch performance. If you are not sure the number of Shards to use, leave the default value.
- The number of shards is used to tune Elasticsearch performance. If you are not sure the number of Shards to use, leave the default value.
- Press the CREATE SITE SEARCH INDEX button.
Populating the Index
To run or schedule an indexing process, select the Job Scheduler tab.
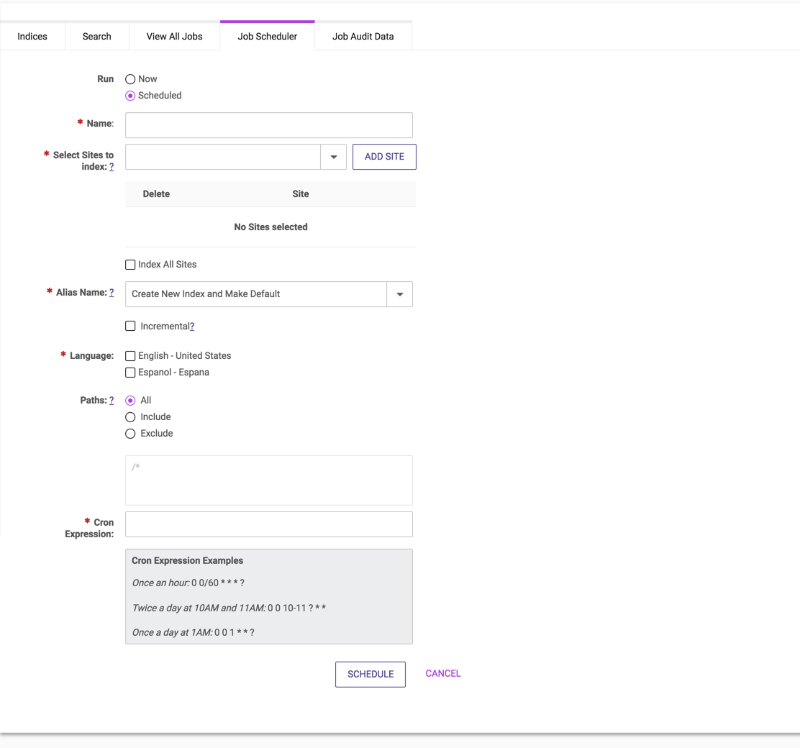
On this page a new job can be either run now or scheduled. Enter the following fields to create a new job:
| Property | Default Value | Description |
|---|---|---|
| Run | Scheduled | A job set to run Now will cause content to be indexed immediately when the SCHEDULE button is clicked. A Scheduled job will be set to run automatically and repeatedly on a schedule you specify via the Cron Expression property. |
| Name | None | The name that will be displayed for the job in the View All Jobs tab. |
| Hosts | None | The host(s) to index.
|
| Alias Name | Create New Index and Make Default | Select the Alias of the index where the content will be added.
|
| Incremental | Unchecked |
|
| Language | None | Check the box for each content Language to include in the index.
|
| Paths Type | All | |
| Paths List | None | Comma separated list of paths to include or exclude.
|
| Cron Expression | None | Specifies when and how often the job will run (and thus when and how often the Site Search index will be updated).
|
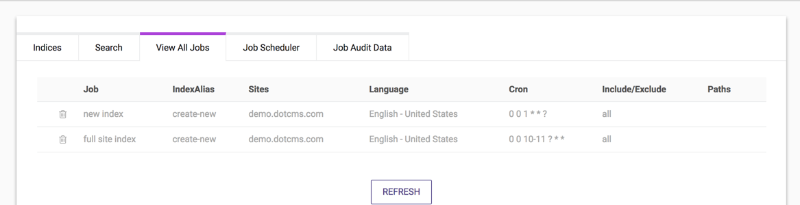
Viewing Scheduled Jobs
To view all currently scheduled Site Search index jobs, select the View All Jobs tab.
- When a job is running, progress of the job will be displayed to the left of the Job Name.
- If a job was created with the Run field set to Now, it will display in the jobs list with the name runningOnce.
- You may only have one runningOnce job at a time.
- If you run a second indexing job with the Run field set to Now before the previous runningOnce job completes, the previous job will be aborted and the indexing from the previous job will not be completed.
- When the runningOnce job finishes it will disappear from the list.
- You may only have one runningOnce job at a time.
Performing Searches Against a Site Search Index
Searching an Index in the Back-End
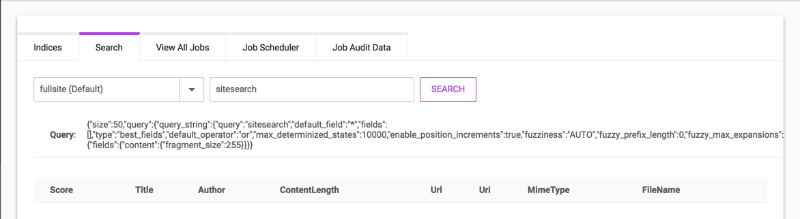
You may perform searches against a Site Search index in the dotCMS back-end to validate that contents of the index. To select an index to search, do one of the following:
- Click on the index from the Indices tab.
- Select the Search tab, and select the name of the index from the drop-down list.
To search the index, enter the search terms in the field to the right of the index name and click the SEARCH button.
The search results display the Score, Title, Author, Content Length, Url, Uri, Mime Type and Filename. At the bottom of the page, the time required to perform the search is displayed, to help you understand and tune the performance of your Site Search index.
For more information on how you can query within your Site Search indexes, please see the SiteSearch Viewtool documentation.
Front-end Site Searches
To perform searches on a Site Search index from the front-end of your site, you must use the SiteSearch viewtool, which allows you to specify the search terms and the Site Search index to search against.
Searches against the Site Search index from the front-end of a site are typically done by creating a form which allows the user to enter their search terms, and then uses the SiteSearch Viewtool to pass the user's search terms to the appropriate Site Search index.
Since you can choose which index to search for each form, you can create different Site Search indexes for different portions of your site. For example, you can have one site search index for the documentation section of your site, another for the support section, another for the products section, and yet another that includes content from all sections of your site in a single index.
For more information and examples of how to use the viewtool, please see the SiteSearch viewtool documentation.
Job Audit Data
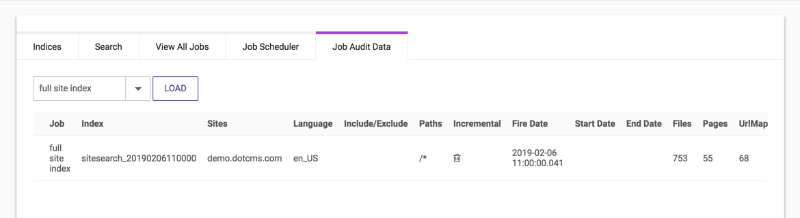
The Job Audit Data tab can be used to help understand and tune the performance of your Site Search indexing jobs. It contains a drop-down list that includes all the jobs which will be executed at least one more time in the future (based on the job's Cron Expression).
Note: Jobs which are scheduled to run Now, jobs which have been deleted, and jobs which have a Cron Expression that will not ever run again in the future will not be displayed here. To view a job in this tab you must schedule the job as a repeating Scheduled job.
To display the audit data for a job, select it from the list and click the LOAD button. All the job information for previous runs of that job will be displayed, with one row for each previous job execution.
Choosing Which Content to Index on a Page
When a Site Search indexing job is run, dotCMS sets the User-Agent header in the HTTP request to DOTCMS-SITESEARCH, to distinguish the indexing job from normal site traffic. This enables you to change how your page is displayed and/or what code and tags are included on the page during Site Search indexing, which allows you to do things like exclude site search indexing from your site analytics and choose which content to display for the Site Search indexing for content whose display varies (such as content which is displayed differently based on Personalization).
The sample code below shows you how to set up a portion of your Page or content to be excluded when the Site Search index is running:
#if($request.getAttribute("User-Agent")!="DOTCMS-SITESEARCH")
## Custom code...
#end
For more information on how dotCMS sets the “User-Agent” property to enable you to change how your content is displayed in different circumstances, please see the Request, Response, and Session documentation.
