

dotCMS content search uses Elasticsearch, which offers two different types of robust syntax to search and retrieve content from the content repository.
The most common search syntax used in dotCMS is an Elasticsearch query string, which is based on the powerful Lucene query syntax. This syntax is used for specifying the query string only, so it is simple to create a query string, but does not provide access to more advanced Elasticsearch features.
The “full” Elasticsearch syntax uses JSON format to specify both the query string (or individual query terms), and additional features and options which can modify the query. This syntax is more complex than the Lucene syntax, requiring more sophisticated formatting, but allows the use of powerful features such as aggregations and geolocation queries which are not available with the Lucene syntax.
Elasticsearch Query String Syntax (Lucene)
Many tools in dotCMS allow you to specify the Lucene query syntax, eliminating the need to use the more complex JSON syntax. When you use a tool in dotCMS that accepts Lucene syntax, dotCMS automatically creates the full Elasticsearch syntax needed to perform the query in the background. You can use the exact same Lucene query syntax in all of the following ways within dotCMS:
- Velocity code:
- Back-end content search
- Back-end search tools:
- The REST API interface.
For more information on how to create Lucene queries, please see the following sections:
Fields Which Can be Searched
Only fields of a Content Type which are indexed can be searched. Indexed fields can include both fields which have been added to a Content Type and system fields.
When searching any field, the Lucene syntax takes the form of field_name:value_to_search_for. You may search for multiple fields in the same Lucene query by including multiple search terms separated by operators or spaces; search terms are automatically combined using an OR operator unless another boolean operator is used.
Searching Specific Fields
dotCMS automatically indexes (and makes searchable) all fields in a Content Type with the System Indexed option checked. Note that the System Indexed option is also automatically selected if you check the User Searchable, Show in List or Unique options on a Content Type field.
All indexed fields can be queried in dotCMS using a [contentTypeName].[field] notation. For example, if you have a “Products” Content Type (Content Type variable name “products”) with a “Product Type” field (field variable name “productType”), then you can search that field for the value “etf” with the following search term: +products.productType:etf.
Note that you can not search non-indexed fields using Elasticsearch queries. If you want to be able to perform queries against a field of your Content Type, you must make that field System Indexed.
System Fields
In addition to the fields selected in the Content Type definition, dotCMS automatically indexes all of the Elasticsearch system properties for every piece of content in the system.
When querying these properties (or when sorting by these properties), you do not need to prefix the Content Type Variable. For example, to query for the word “Bond” in the “Title” field of the “Products” Content Type in the dotCMS starter site, you can use the query +title:bond (instead of +products.title:bond), and to sort by the last modification date, you can sort by just modDate (instead of products.modDate).
For more information on each of these system properties, please see the How Content is Mapped to Elasticsearch documentation.
Related Content
Every Content Type which has a relationship to another Content Type has one additional “hidden” field added to the index for each relationship. This allow you to search for related content from the Content Type using Elasticsearch Query String Syntax (Lucene).
Warning: if you are on a child object you will not be able to get the related parent this way instead you can use Content Rest API or Content Viewtool. See Parent Child Relationships for more information
Search Terms
Search terms consist of one or more words, delineated by Operators. Understanding how Elasticsearch parses search terms will help you select appropriate operators and ensure your queries work as intended.
Case-Insensitive
Elasticsearch queries are case-insensitive; all query terms are converted to lower case both when the indexes are created and when queries are submitted.
Full Word Parsing
When you specify search terms in Lucene syntax, by default each term specifies a full word in the selected field.
For example, if you search for “ape” in a field, by default the search will return only content items with the full word “ape” in the selected field. However the search will not return content in which “ape” is only part of a word in the field (such as part of the words “cape” or “aped”).
If you wish to specify that a search term should match part of a word as well, use Wildcards to specify how the term should be matched.
Word Combinations
To match a combination of words in a specific order, enclose all words in double quotes. For example, if you search for the term "final exam" (including the double quotes), the query will only return content items where the word “exam” directly follow the word “final”, with no intervening words; content items which contain both words, but where the words are in reverse order, or are separated by other words (such as “all exam grades are final”), will not be returned.
Null Values
Lucene syntax does not have a way to directly specify the existence of Null (empty) values in the search terms. However, a combination of operators can be used to identify when a field has a value within a specific range.
For example, if you have a Content Type with a Velocity variable name of typeVar, and it contains a Binary field with a Velocity variable name of binaryVal, then the following query can be used to determine if the field contains a value:
+contentType:typeVar +typeVar.binaryVal:([0 TO 9] [a TO z] [A TO Z])
This query uses three different value ranges, separated by spaces (where each space is interpreted as an OR operator).
Operators
The following are some of the most common operators used in Lucene query strings; you can use these operators to build most Lucene queries. If you need to create more complex queries, consider using the full Elasticsearch syntax. For more information on Lucene query syntax, please see the official Lucene documentation.
| Name | Operator |
|---|---|
| Required | + |
| Prohibit | - |
| Boolean AND | && |
| Boolean OR | || |
| Boolean NOT | ! |
| Search All Fields | catchall |
| Value Range | [... TO ...] |
| Date Range | [{date} TO {date}] |
| Single Character Wildcard | ? |
| Multiple Character Wildcard | * |
| Field Grouping | (, ) |
| Fuzzy Search | ~ |
| Boost Terms | ^ |
| Escape Character | \ |
Default Operator: OR (Space Between Terms)
If there is no operator between terms (in other words, just a space between terms), the terms will automatically be joined as if an OR operator had been inserted between the terms.
Note, however, that when you have terms which match multiple values for the same field within parentheses (for example, +field:(term1 term2), the space alone may not work as expected. When you wish to match multiple values for the same field, you should use one of the following methods to ensure the terms are matched properly:
- Use an explicit
ORoperator instead of an implicit OR (via a space).- Example:
+field:(term1 OR term2)
- Example:
- Explicitly specify the field name for each separate value to match.
- Example:
+(field:term1 field:term2)
- Example:
- Enclose each search term in quotes.
- Example:
+field:("term1" "term2")
- Example:
Required (+)
The required operator (+) only returns items which have the term after the “+” in the specified content field. If the required operator is not included, then results may be returned which do not include the term, as long as they meet the other requirements of the query string (such as matching other specified fields or search terms); by using the required operator, you can ensure that search results will exclude any results which do not include specific search terms.
For example, the following query will only return blog articles whose body includes the term “investment”. The search results may also have the term “JetBlue”. This means that search results which include both “investment” and “JetBlue” will receive higher scores (and thus may be sorted near the top of the results); but items which include “investment” but do not include “JetBlue” will still be returned, while items which include “JetBlue” but do not include “investment” will not be returned.
+contentType:Blog +Blog.body:(+"investment" "JetBlue")
Prohibit (-)
The Prohibit (-) operator excludes documents that contain the term after the - symbol. For example, the following query returns all the employees whos first name begins with the letter “R”, but whose last name does NOT begin with the letter “A”:
+contentType:Employee +(Employee.firstName:R*) -(Employee.lastName:A*)
Note: For a description of the asterisk character (*), please see Multiple Character Wildcard, below.
Boolean Operators [AND (&&), OR (||), and NOT (!)]
AND (&&)
The AND operator (&&) matches content where both terms exist in the content field(s) being queried. For example, the following query returns only the blogs where the word “business” and “Apple” BOTH appear in the blog body field:
+contentType:Blog +Blog.body:("business" && "Apple")
Note: The order the fields appear in the results do not matter for the AND operator. The example would return both results where the word “business” appears before the word “Apple” and results where the word “business” appears after the word “Apple”.
OR (||)
The OR operator (||) links two terms and finds a matching document if either of the terms exist in the content field(s) being queried. The OR operator is the equivalent of a union between sets. For example, the following query returns all items which include either the word “analysts” or the word “investment” in the body:
+contentType:Blog +Blog.body:("analysts" || "investment")
NOT (!)
The NOT (!) operator excludes documents that contain the term after the ! symbol. For example, the following query returns all blog artices with the word “investment” in the body, but do NOT have the term “JetBlue” in the body:
+contentType:Blog +Blog.body:("investment" !"JetBlue")
Search All Fields (Catchall)
To search all fields in the content (rather than a specific field), use catchall in the same way you would specify an individual field name. For example, the following query returns all items which have the word “fund” in any searchable field in the content:
+contentType:Products +catchall:*fund*
For more information on using the catchall search term, please see the Search within All Content Fields documentation.
Value Range
Use square brackets around a beginning and end value with the word “TO” between them to search for values that fall within the range (inclusive). The start and end values must be numbers, characters (not enclosed with quotes), or dates (see below), but cannot be strings.
Important: The TO in the term must be all uppercase.
For example, the following query returns all News items with a Title that begins with the letters 'A', 'B', or 'C' (see Wildcards, below for the use of the asterisk (*)):
+contentType:News +News.title_dotraw:[A TO C]*
Note that, when performing a character range search on any text-based field, the Raw field must be used
Date Range
You can search for a range of Dates (and Times) using the Value Range syntax. The syntax is the same, but you must ensure that you use the proper format to specify the start and end dates, to ensure dotCMS will recognize the value as a date.
The default date format that dotCMS uses (and expects) is in the form yyyyMMddHHmmss. Some other formats can be used, but it is recommended that all new queries use this default format, as support for different date formats sometimes changes in different versions of Elasticsearch.
For example, the following query returns all News items with publish dates between January 1, 2011 at 2:30 PM and December 31, 2015 at 2:30 PM:
+contentType:News +News.sysPublishDate:[20110101143000 TO 20151231143000]
Note: Searching date ranges via the Content API requires slightly different date formatting.
Wildcards
You may include wildcard characters to allow your query to return results which match some common portion of the search term, but which vary in other portions of the field.
Single Character Wildcard (?)
The question mark character (?) will match any single character, so any result which includes any character in the respective position of the question mark will be returned as long as the rest of the query string matches. For example, the following query returns all Employees whose first name includes “Mari”, followed by any character. Search results will include employees with the first name “Maria” or “Marie” (or any other 5 letter first name which begins with “Mari”).
+contentType:Employee +Employee.firstName:Mari?
Multiple Character Wildcard (*)
The asterisk character (*) can be used before or after a text string in a query to allow a match of any characters (or no characters) before or after a match of the specified text. For example, the following query string returns all employees whose first name begins with the letter R:
+contentType:Employee +Employee.firstName:R*
Field Grouping
You can search for multiple fields and return all matches by including the search terms for all fields within parentheses. For example, the following query returns both employees whose first name begins with the letter R and those whose last names begin with the letter J:
+contentType:Employee +(Employee.firstName:R* Employee.lastName:J*)
Note:
- Since there is no operator between the
Employee.firstName:R*andEmployee.lastName:J*terms, the search returns items which match either search term (e.g. logical OR).- To search for employees who have both a first name beginning with
RAND a last name beginning withJ, you would need to add an AND operator between the terms. - e.g.,
+contentType:Employee +(Employee.firstName:R* && Employee.lastName:J*)
- To search for employees who have both a first name beginning with
Fuzzy Search
dotCMS search queries support fuzzy searches based on the Levenshtein Distance — the number of single-character additions, deletions, or edits needed to match. To do a fuzzy search use the tilde, “~“, symbol at the end of a single-word Term. An additional (optional) parameter can specify the required similarity. The value is an integer representing edit distance; if none is specified, it defaults to 2. The first example below (without the parameter), returns blogs with pass, passes, passe, passed, bypass, passel, etc. Out of that same list, however the second example would only return pass or passe.
+contentType:Blog +Blog.body:pass~
+contentType:Blog +Blog.body:pass~1 (optional)
Boost Terms
Queries can be sorted by score to make the search results that contain the query terms more times appear at the top of the list. Normally, when sorting by score, all query terms are treated equally, so any search result that includes a search term more times than another search result will appear closer to the top of the results list.
However queries can be score weighted to give higher or lower listing priority to different search terms. Each term in a query can be weighted with a caret (^), followed by an integer number to give the term a weight. When the query results are sorted by Score, the search results that contain higher weighted terms will appear at the top of the results list, and the results with lower weighted terms will appear at the bottom of the list.
In the following example, “American” has a higher weight than “invest”. So when “Score” is used as a sort parameter, a search result that include the term “American” will usually appear above a result that includes the term “invest”, even if the term “American” appears in first result fewer times than the “invest” term appears in the second result.
+contentType:News +(News.title:*American*^10 News.title:*invest*^2)
Here is an example of a code which uses this query and sorts by Score in a news content pull:
#foreach($news in $dotcontent.pull("+contentType:News +(News.title:*American*^10 News.title:*invest*^2)",10,"Score"))
$velocityCount.$news.headline
#end
Negative Boosting
Lucene syntax does not support negative Boost values. However you can achieve a result similar to a negative boost by giving a positive boost to all content which does not match a given term. This can be accomplished by adding the term (*:* -[term])^[boost] to the query.
For example, the following code repeats the previous query, but reduces the score of all results which contain the term “retirement” (by boosting the score of all results which do not contain the term “retirement”):
#foreach($news in $dotcontent.pull("+contentType:News +(News.title:*American*^10 News.title:*invest*^2) (*:* -retirement)^99",10,"Score"))
$velocityCount.$news.headline
#end
Escaping Special Characters
Certain characters have special meaning in a query string, so if you with to search for these characters in your query, you must escape the characters to ensure they aren't interpreted by the query parser. Use a backslash before a special character to escape it in a search query. The following special characters must be escaped:
| Character / Term | Text | Escaped |
|---|---|---|
| Plus | + | \+ |
| Minus | - | \- |
| And | && | \&& |
| Or | `\ | \ |
| Not | ! | \! |
| Parentheses | (, ) | \(, \) |
| Curly braces | {, } | \{, \} |
| Square brackets | [, ] | \[, \] |
| Caret | ^ | \^ |
| Double quote | " | \" |
| Tilde | ~ | \~ |
| Asterisk | * | \* |
| Question mark | ? | \? |
| Colon | : | \: |
| Backslash | \ | \\ |
Note:
&&and||only need to be escaped if you wish to query for the two characters together.- If you wish to search for a single
&or|character, you do not need to escape them. - However it is always good practice to escape even the individual characters, to make it clearer to someone else what the query is intended to search for.
- If you wish to search for a single
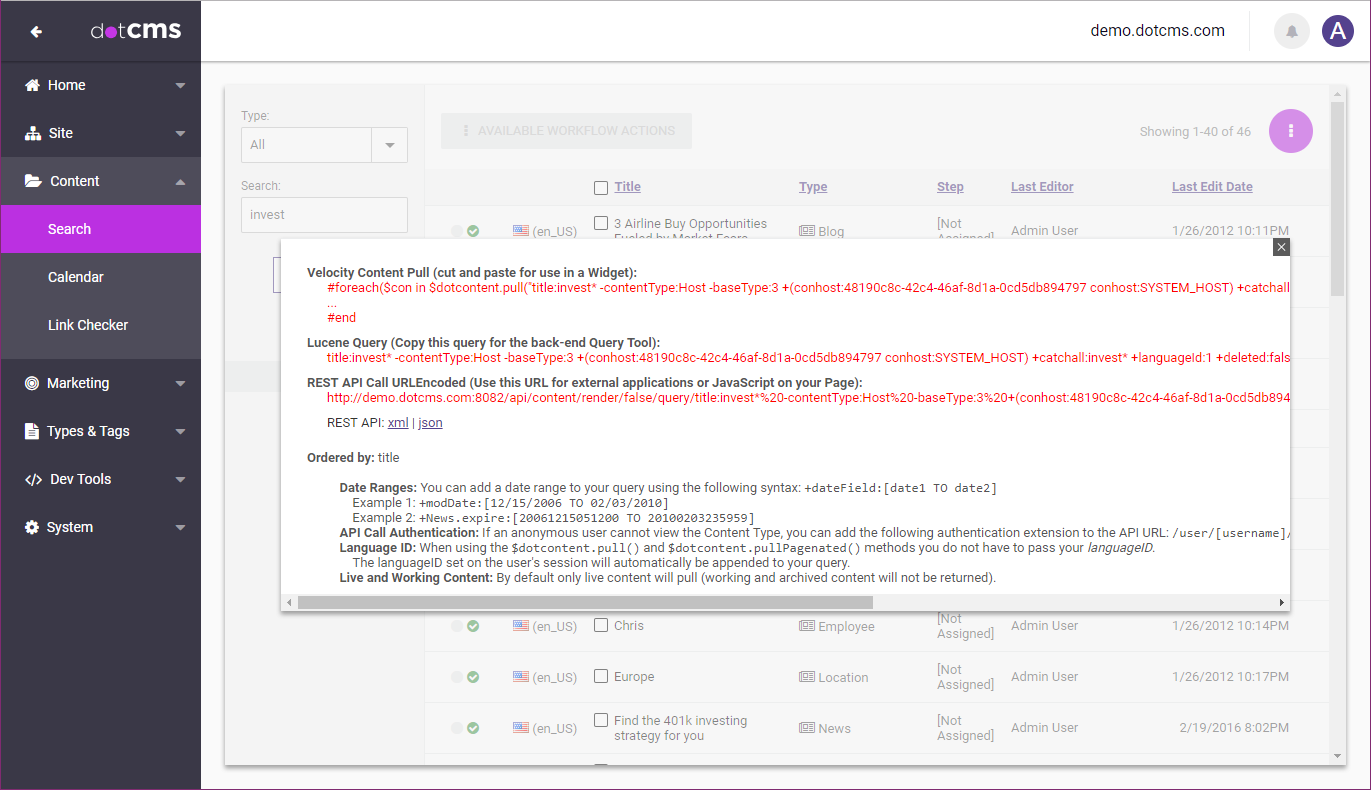
Using the Content Search Screen to Build Lucene Queries
You can use the “Show Query” button on the Content Search screen to display and build your dynamic content queries.
To build your Lucene query using the Content Search screen:
- Open the Content Search screen (Content -> Search).
- Use the filters in the left sidebar to select the content you want to include in your Lucene query.
- If desired, select the header of the appropriate column to sort the displayed contents.
- Click the SEARCH button at the bottom of the left sidebar, and select Show Query.
- In the popup window, select the query (in red) shown under the Lucene Query header.
- Note that if you are creating a Velocity content pull or performing a content pull via a REST API call, there are sections in the popup that you can use to pull the code for those types of pulls in their entirety.
Full Elasticsearch Syntax (JSON)
The full Elasticsearch syntax is used in the dotCMS back-end ES Search Tool and in Velocity using the Elasticsearch Viewtool.
Full Elasticsearch syntax uses JSON format which supports many different types of queries, features, and options. Depending on the type of query performed, full Elasticsearch syntax may require individual query terms or a query string (specifically, in full ElasticSearch queries that require a “query” term, the query string uses Lucene query syntax, as described above).
Examples
For some examples of full Elasticsearch query syntax, please see the following:
- The Elasticsearch Examples documentation.
- The ES Search Tool documentation.
- The ES Search Tool Help button.
For complete documentation on Elasticsearch syntax (including examples for additional features and options), please see the official Elasticsearch documentation.
